
客户端强制kill -9杀掉mfsmount进程,需要先umount,然后再mount。否则会提示:
fuse: bad mount point `/usr/mfstest/': Transport endpoint is not connected
see: /usr/local/mfs/bin/mfsmount -h for help
2、matser、metalogger、chunker、client端,服务器关机(init0)和重启(init6)时,程序都是正常关闭,无需修复。
3、master启动后,metalogger、chunker、client三个元素都能自动与master建立连接。
正常启动顺序:matser---chunker---metalogger---client
关闭顺序:client---chunker---metalogger---master
但实际中无论如何顺序启动或关闭,未见任何异常。
4、整个mfs体系中,直接断电只有master有可能无法启动。
使用mfsmetarestore -a修复才能启动,如果无法修复,使用metalogger上的备份日志进行恢复。(几次测试发现:如果mfsmetarestore -a无法修复,则使用metalogger也无法修复)。
强制使用metadata.mfs.back创建metadata.mfs,可以启动master,但应该会丢失1小时的数据。
mfs开发小组针对此问题回信:明确表示会丢失故障点到上一个整点之间的数据。和之前我猜测的一致。因为对mfs的操作日志都记录到changelog.0.mfs里面。changelog.0.mfs每小时合并一次到metadata.mfs中,如果突然断电,则changelog.0.mfs里面的信息就没有合并到metadata中,强制使用metadata.mfs.back创建metadata.mfs,就会导致丢失changelog.0.mfs里的数据。
MFS小组原文:metadata.mfs.back contains metadata from within the last hour - you can run the master server based on this file but you lose metadata from last hour from the outage. It mainly concerns the files which were saved or modified during this time. The system would be consistent but we'll lack the last changes.
Command "mfsmetarestore" tries to add to "metadata.mfs.back" all the changes which taken place from last save of it till the moment of outage.
针对之前遇到的不能修复的故障,咨询是否能够在以后版本中提供恢复到某个version号,对方回复:
Maybe in the future we'll implement two options to "metarestore":
- ignore any erroers, recover as much as it is possible
- save the file after encountering the first error
直接断电测试过程,使用mfsmetarestore –a无法修复,使用metalogger也无法修复的情况较少发生。5次只有一次无法修复。
5、chunker的维持:chunker的块(chunks)能够自动复制或删除
对一个目录设定“goal”,此目录下的新创建文件和子目录均会继承此目录的设定,但不会改变已经存在的文件及目录的copy份数。但使用-r选项可以更改已经存在的copy份数。
goal设置为2,只要两个chunker有一个能够正常运行,数据就能保证完整性。
假如每个文件的goal(保存份数)都不小于2,并且没有under-goal文件(可以用mfsgetgoal –r和mfsdirinfo命令来检查),那么一个单一的chunkserver在任何时刻都可能做停止或者是重新启动。以后每当需要做停止或者是重新启动另一个chunkserver的时候,要确定之前的chunkserver被连接,而且要没有under-goal chunks。
实际测试时,传输一个大文件,设置存储2份。传输过程中,关掉chunker1,这样绝对会出现有部分块只存在chunker2上;启动chunker1,关闭chuner2,这样绝对会有部分块只存在chuner1上。
把chunker2启动起来。整个过程中,客户端一直能够正常传输。
在客户端查看,一段时间内,无法查看;稍后一段时间后,就可以访问了。文件正常,使用mfsfileinfo 查看此文件,发现有的块分布在chunker1上,有的块分布在chuner2上。
使用mfssetgoal 2和mfssetgoal -r 2均不能改变此文件的目前块的现状。
但使用mfssetgoal -r 1后,所有块都修改成1块了,再mfssetgoal -r 2,所有块都修改成2份了。
测试chunker端,直接断电情况下,chunker会不会出问题:
a、数据传输过程中,关掉chunker1,等待数据传输完毕后,开机启动chunker1.
chunker1启动后,会自动从chunker2复制数据块。整个过程中文件访问不受影响。
b、数据传输过程中,关掉chunker1,不等待数据传输完毕,开机启动chunker1.
chunker1启动后,client端会向chunker1传输数据,同时chunker1也从chunker2复制缺失的块。
如果有三台chunker,设置goal=2,则随机挑选2个chunker存储。
如果有一个chunker不能提供服务,则剩余的2个chunker上肯定有部分chunks保存的是一份。则在参数(REPLICATIONS_DELAY_DISCONNECT = 3600)后,只有一份的chunks会自动复制一份,即保存两份。
保存两份后,如果此时坏掉的chunker能够提供服务后,此时肯定有部分chunks存储了三份,mfs会自动删除一份。
When I added a third server as an extra chunkserver it looked like it started replicating data to the 3rd server even though the file goal was still set to 2. Yes. Disk usage ballancer uses chunks independently, so one file could be redistributed across all of your chunkservers.
当我增加第三个服务器做为额外的chunkserver时,虽然goal设置为2,但看起来第三个chunkserver从另外两个chunkserver上复制数据。
是的,硬盘空间平衡器是独立地使用chunks的,因此一个文件的chunks会被重新分配到所有的chunkserver上。
6、chunks修复 :mfsfilerepair
mfsfilerepair deals with broken files (those which cause I/O errors on read operations) to make them partially readable. In case of missing chunk it fills missing parts of file with zeros; in case of chunk version mismatch it sets chunk version known to mfsmaster to highest one found on chunkservers. Note: because in the second case content mismatch can occur in chunks with the same version, it’s advised to make a copy (not a snapshot!) and delete original file after "repairing".
mfsfilerepair用来处理坏文件(如读操作引起的I/O错误),使文件能够部分可读。在丢失块的情况下使用0对丢失部分进行填充;在块的版本号(version)不匹配时设置块的版本号为master上已知的能在chunkerservers找到的最高版本号;注意:因为在第二种情况下,可能存在块的版本号一样,但内容不匹配,因此建议在文件修复后,对文件进行拷贝(不是快照!),并删除原始文件。
Client端大文件传输过程中,强制拔下master主机电源,造成master非法关闭,使用mfsmetarestore -a修复后,master日志报告有坏块:
Jan 19 17:22:17 ngmaster mfsmaster[3250]: chunkserver has nonexistent chunk (000000000002139F_00000001), so create it for future deletion
Jan 19 17:22:18 ngmaster mfsmaster[3250]: (192.168.5.232:9422) chunk: 000000000002139F creation status: 20
Jan 19 17:25:18 ngmaster mfsmaster[3250]: chunk 000000000002139F has only invalid copies (1) - please repair it manually
Jan 19 17:25:18 ngmaster mfsmaster[3250]: chunk 000000000002139F_00000001 - invalid copy on (192.168.5.232 - ver:00000000)
Jan 19 17:26:43 ngmaster mfsmaster[3250]: currently unavailable chunk 000000000002139F (inode: 135845 ; index: 23)
Jan 19 17:26:43 ngmaster mfsmaster[3250]: * currently unavailable file 135845: blog.xxx.cn-access_log200904.tar.gz
Client端使用mfsfilerepair修复
[root@localhost mfstest]# /usr/local/mfs/bin/mfsfilerepair blog.xxx.cn-access_log200904.tar.gz
blog.xxt.cn-access_log200904.tar.gz:
chunks not changed: 23
chunks erased: 1
chunks repaired: 0
查看master日志,发现:
Jan 19 17:30:17 ngmaster mfsmaster[3250]: chunk hasn't been deleted since previous loop - retry
Jan 19 17:30:17 ngmaster mfsmaster[3250]: (192.168.5.232:9422) chunk: 000000000002139F deletion status: 13
Jan 19 17:35:16 ngmaster mfsmaster[3250]: chunk hasn't been deleted since previous loop - retry
Jan 19 17:35:16 ngmaster mfsmaster[3250]: (192.168.5.232:9422) chunk: 000000000002139F deletion status: 13
Client端执行以下操作后,master不再报告相关信息:
mv blog.xxt.cn-access_log200904.tar.gz blog.xxt.cn-access_log200905.tar.gz
7、chunker的空间
每一个chunkserver的磁盘都要为增长中的chunks保留些磁盘空间,从而达到创建新的chunk。只有磁盘都超过256M并且chunkservers报告自由空间超过1GB总量才可以被新的数据访问。最小的配置,应该从几个G 字节的存储。
When doing df -h on a filesystem the results are different from what I would expect taking into account actual sizes of written files.Every chunkserver sends its own disk usage increased by 256MB for each used partition/hdd, and a sum of these master sends to the client as total disk usage. If you have 3 chunkservers with 7 hdd each, your disk usage will be increased by 3*7*256MB (about 5GB). Of course it's not important in real life, when you have for example 150TB of hdd space.
每个chunkerserver每次以256M的磁盘空间进行申请,客户端查看得到的磁盘总使用情况的是每个chunkerserver使用量的总和。例如:如果你有3个chunkerserver,7个分区磁盘,每次你的硬盘使用会增加3*7*256MB (大约5GB)。假如你有150T的硬盘空间,磁盘空间就不用过多考虑了。
There is one other thing. If you use disks exclusively for MooseFS on chunkservers df will show correct disk usage, but if you have other data on your MooseFS disks df will count your own files too.
另外,如果你的chunkservers使用专用的磁盘,df将显示正确的磁盘使用情况。但是如果你有其他的数据在你的MooseFS磁盘上,df将会计算你所有的文件。
If you want to see usage of your MooseFS files use 'mfsdirinfo' command.
如果你想看你的MooseFS文件的使用情况,请使用'mfsdirinfo'命令。
8、快照snapshot
可以快照任何一个文件或目录,语法:mfsmakesnapshot src dst
但是src和dst必须都属于mfs体系,即不能mfs体系中的文件快照到其他文件系统。both elements must be on the same device。
Mfsappendchunks:追加chunks到一个文件
append file chunks to another file. If destination file doesn't exist then it's created as empty file and then chunks are appended
snapshot测试:
a、对一个文件做snapshot后,查看两个文件的块,是同一个块。把原文件删除,原文件删除后(回收站中最初可以看到,但一段时间后,回收站中就彻底删除了),snapshot文件仍然存在,并且可以访问。使用mfsfileinfo查看,发现仍然是原来的块。
b、对一个文件做snapshot后,查看两个文件的块,是同一个块。把原文件修改后,发现原文件使用的块名变了,即使用的是一个新块。而snapshot文件仍然使用原来的块。
9、回收站 trash bin
设置文件或目录的删除时间。一个删除的文件能够存放在“ 垃圾箱”中的时间称为隔离时间, 这个时间可以用mfsgettrashtime 命令来查看,用mfssettrashtime 命令来设置。单位为秒。
单独安装或挂载MFSMETA 文件系统(mfsmount -m mountpoint),它包含目录/ trash (包含仍然可以被还原的删除文件的信息)和/ trash/undel (用于获取文件)。
把删除的文件,移到/ trash/undel下,就可以恢复此文件。
在MFSMETA 的目录里,除了trash 和trash/undel 两个目录,还有第三个目录reserved,该目录内有已经删除的文件,但却被其他用户一直打开着。在用户关闭了这些被打开的文件后,reserved 目录中的文件将被删除,文件的数据也将被立即删除。此目录不能进行操作。
10、文件描述符
1.5.12版本,进行大量小文件写时,出现了一个严重错误,有可能和操作系统文件描述符有关。操作系统默认文件描述符为1024.
1.6.11版本默认为100000
建议上线时,master和chunker修改文件描述符,即修改/etc/security/limits.conf添加
* - nofile 65535
11、mfscgiserv
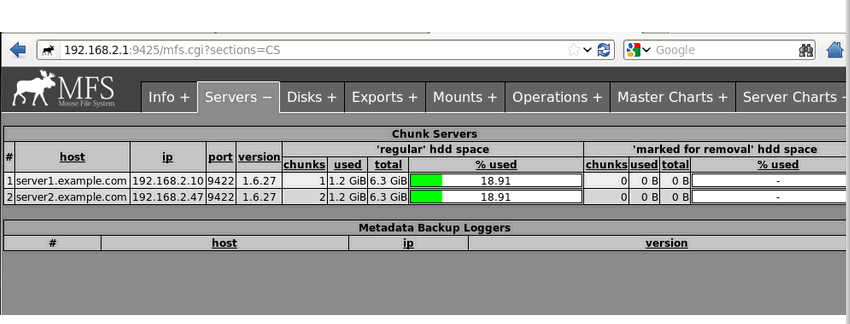
Mfscgiserv 是一个python 脚本, 它的监听端口是9425 ,使用/usr/local/mfs/sbin/mfscgiserv 来直接启动,使用浏览器就可全面监控所有客户挂接, chunkserver 及master server,客户端的各种操作等。

