
某天,月黑风高,寒风凌厉。迷糊中,一阵急促的电话响起,来电告知,数个机房的带宽暴涨,需要立即处理,否则IDC服务商要拔网线了。一看时间,大概是凌晨2点了,真悲催啊!
先登录监控系统查看流量。平时流量最大的一个服务器的带宽跑满1G了(因为当时急着处理故障,没留下截图),而正常情况下,它的带宽峰值稳定在600M-700M/s的样子,如下图所示:
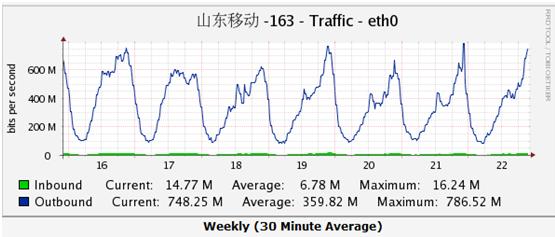
查看其它服务器,带宽图基本拉成一条直线,把100M跑满了(这些机器性能差,带宽为100M)。

尽管多个机房多个服务器带宽都超平常很多,基本可以确定是出问题了。但心里还是不放心,担心是cacti监控不准或者出了故障。因此又单独登录数个流量大的服务器,使用iptraf这样的工具实时查看,结果真的与cacti给出的结果一致。
这是一个下载业务,总带宽峰值大概在3Gb/s的样子。其结构分为三层:源站、中转层、边缘层。其业务流程如下图所示:
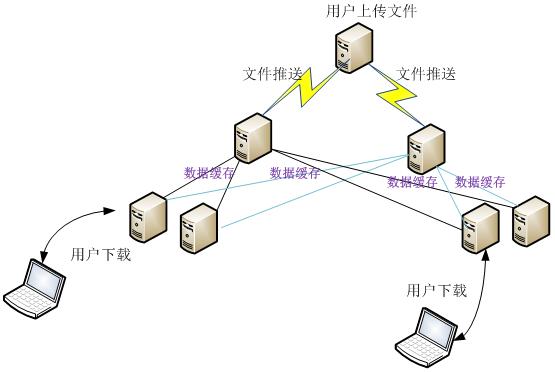
1、用户通过web接口编辑和上传文件到源站服务器;
2、源站用rsync同步文件到中转服务器;
3、边缘服务器配置成缓存,然后根据需要从中转服务器抓取所需的对象存储起来。
为了提高可用性和负载均衡,边缘服务器从2个中转服务器抓取文件。
一般来说,引起流量暴涨的原因无外乎有:遭受攻击、网站市场推广、系统或程序异常、木马程序。通过询问相关市场人员,答复说近期没有任何市场推广;再问程序员,有没有修改程序或新增插件,答复都是否定的。再让管理人员查看后台统计数据,但统计数据并没有跟流量同步暴增。由此判断,出问题的原因只剩下系统异常和黑客攻击两种情况。被植入木马的几率很小:程序是通过vpn上传的,并且只有静态内容。
情况紧急,不可能每个服务器都登录一片。因此先从流量最大的查起,再查流量次大的。检查的项目包括:
(1)系统日志:看是否有内核报错;
(2)Web日志,统计ip来源是否过于集中;
(3)查看tcp状态,了解请求情况;
(4)用工具iptraf查看连接数最多的ip。
通过上述措施,得知连接数最多的ip不是来自用户,而是来自服务器之间的相互请求。通过查出来的ip,登录改服务器,看是否发生了什么?通过检查进程、系统日志、网络状况都未找到原因。随手执行了一下crontab –l 看有没有什么自动任务,结果发现有一个脚本,而且是每10钟执行一次。我印象中没写个这样一个脚本的。打开一看,内容如下:
#!/bin/bash
Path=`grep proxy_cache_path /usr/local/nginx/conf/vhosts/apk_cache.sery.com.conf |awk '{print $2}'|sed 1d`
for i in `ls $Path`; do
grep -a -r apk $Path/$i/* | strings |grep "KEY:" >/tmp/cache_list$i.txt
grep -v apk$ /tmp/cache_list$i.txt >> /tmp/del$i.txt
rm -rf `grep -v apk$ /tmp/cache_list$i.txt|awk -F: '{print $1}'`
#echo $Path/$i
sleep 60
done
rm -rf /tmp/cache_list*
这个脚本要结合具体场景才能弄明白,因为某些原因,这里不再分析它;总之,这个脚本的作用,就是在缓存目录查询一些文件是否存在,如果存在,就删除它。
上述操作的结果,就是缓存文件刚存在,不久就被干掉。当用户需要下载这个文件时,边缘服务器却没有缓存,因此只好回源(向中转服务器抓取)。正常情况下,会缓存很长一段时间,但因为这个脚本,过一会又把它干掉了。这就导致不断的大量的回源,流量就暴涨了。未避免风险,没直接删除这个脚本,而在crontab计划任务里把它注释掉。逐一在边缘服务器排查,注释掉这个任务。
观察流量图,带宽耗费逐步下降,10-20分钟后,趋于正常了。打一通电话后,继续睡觉。
【编辑推荐】
