
前提:现在有主从结构,主库没有配置持久化,从库配置AOF。
(主库用来备份和写服务,从库用来提供读服务)
场景:哪天主库突然宕了,怎么办? www.2cto.com
方法:连上从库,做save操作。将会在从库的data目录保存一份从库
最新的dump.rdb文件。将这份dump.rdb文件拷贝到主库的data目录下。
再重启主库。
就因为这个我想到了用集群的方案,但是redis官方没有mysql那样的master-
master的模式~ 这样的情况下,只能咱们自己想办法了~
实现的原理~
当 Master 与 Slave 均运作正常时, Master负责读,Slave负责同步;
当 Master 挂掉,Slave 正常时, Slave接管服务,同时关闭主从复制功能;
然后依次循环。
这样,两台redis服务器中的任何一台挂掉,都会由另一台继续提供服务,不会对网站形
成可察觉的影响,也不会丢失数据。
你也可以实现
当 Master 恢复正常,则从Slave同步数据,同步数据之后关闭主从复制功能,恢复
Master身份,于此同时Slave等待Master同步数据完成之后,恢复Slave身份。
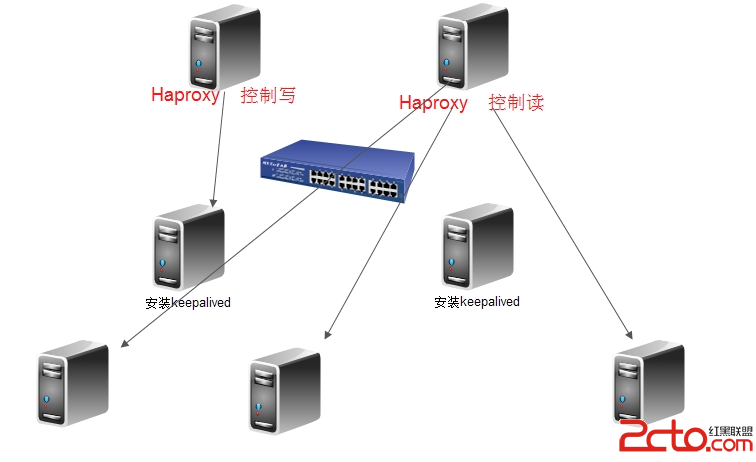
高可用方面
需要把读写进行分离的,写的话,就指向到一个vip~ 那两个主 用keepalived加脚本进行判断。
读的话,尽量用haproxy进行分流,这样的话,哪怕一个从down的话,haproxy会自动剔除的~
redis安装~
wget http://redis.googlecode.com/files/redis-2.2.13.tar.gz
tar -zxf redis-2.2.13.tar.gz
cd redis-2.2.13
make
make install
keepalived的安装~
tar -xzvf keepalived-1.1.20.tar.gz
cd keepalived-1.1.20
./configure --prefix=/usr/local/webserver/keepalived
make
make install
cp /usr/local/webserver/keepalived/sbin/keepalived /usr/sbin
cp /usr/local/webserver/keepalived/etc/sysconfig/keepalived /etc/sysconfig
cp /usr/local/webserver/keepalived/etc/rc.d/init.d/keepalived /etc/init.d
mkdir /etc/keepalived
cp /usr/local/webserver/keepalived/etc/keepalived/keepalived.conf /etc/keepalived
安装完之后,具体说下高可用性的部分,下面是 主的keepalived.conf 的配置文件~
用killall -0 redis-server 来判断进程的存活~
也可以用checkredis.sh 这个脚本~
【大家可以写简单点~】 这个方法是redis自带的一个判断服务存活的程序
#!/bin/bash
REDIS_HOME="/home/redis"
REDIS_COMMANDS="/home/redis/src" # The location of the redis binary
REDIS_MASTER_IP="172.16.0.180" # Redis MASTER ip
REDIS_MASTER_PORT="6379" # Redis MASTER port
ERROR_MSG=`${REDIS_COMMANDS}/redis-cli PING`
#
# Check the output for PONG.
#
if [ "$ERROR_MSG" != "PONG" ]
then
# redis is down, return http 503
/bin/echo -e "HTTP/1.1 503 Service Unavailable\r\n"
/bin/echo -e "Content-Type: Content-Type: text/plain\r\n"
/bin/echo -e "\r\n"
/bin/echo -e "Redis is *down*.\r\n"
/bin/echo -e "\r\n"
exit 1
else
# redis is fine, return http 200
/bin/echo -e "HTTP/1.1 200 OK\r\n"
/bin/echo -e "Content-Type: Content-Type: text/plain\r\n"
/bin/echo -e "\r\n"
/bin/echo -e "Redis is running.\r\n"
/bin/echo -e "\r\n"
exit 0
fi
在变为backup的状态下,所运行的服务,为主的时候所运行的服务~
global_defs {
router_id DBPOOL_01
}
vrrp_script chk_redis {
script "killall -0 redis-server"
interval 2
}
vrrp_instance VI_ETH0 {
interface eth0
virtual_router_id 100
nopreempt
priority 200
advert_int 1
state BACKUP
track_script {
chk_redis
}
virtual_ipaddress {
172.16.0.180
}
notify_master "/opt/redis.sh -m"
notify_backup "/opt/redis.sh -s"
notify_fault "/opt/redis.sh -k"
}
下面是从的配置
global_defs {
router_id DBPOOL_01
}
vrrp_script chk_redis {
script "killall -0 redis-server"
interval 2
}
vrrp_instance VI_ETH0 {
interface eth0
virtual_router_id 100
nopreempt
priority 100
advert_int 1
state BACKUP
track_script {
chk_redis
}
virtual_ipaddress {
172.16.0.180
}
notify_master "/opt/redis.sh -m"
notify_backup "/opt/redis.sh -s"
notify_fault "/opt/redis.sh -k"
}
下面是 /opt/redis.sh 的脚本
#!/bin/sh
#
# Script to start Redis and promote to MASTER/SLAVE
# Usage Options:
# -m promote the redis-server to MASTER
# -s promote the redis-server to SLAVE
# -k start the redis-server and promote it to MASTER
#
REDIS_HOME="/home/redis"
REDIS_COMMANDS="/home/redis/src" # redis执行文件的目录
REDIS_MASTER_IP="172.16.0.180" # Redis MASTER ip
REDIS_MASTER_PORT="6379" # Redis MASTER port
REDIS_CONF="redis-mdb.conf" # 配置文件
E_INVALID_ARGS=65
E_INVALID_COMMAND=66
E_NO_SLAVES=67
E_DB_PROBLEM=68
error() {
E_CODE=$?
echo "Exiting: ERROR ${E_CODE}: $E_MSG"
exit $E_CODE
}
start_redis() {
alive=`${REDIS_COMMANDS}/redis-cli PING`
if [ "$alive" != "PONG" ]; then
${REDIS_COMMANDS}/redis-server ${REDIS_HOME}/${REDIS_CONF}
sleep 1
fi
}
start_master() {
${REDIS_COMMANDS}/redis-cli SLAVEOF no one
}
start_slave() {
${REDIS_COMMANDS}/redis-cli SLAVEOF ${REDIS_MASTER_IP} ${REDIS_MASTER_PORT}
}
usage() {
echo -e "Start Redis and promote to MASTER/SLAVE - version 0.3
(c) Alex Williams - www.alexwilliams.ca"
echo -e "\nOptions: "
echo -e "\t-m\tpromote the redis-server to MASTER"
echo -e "\t-s\tpromote the redis-server to SLAVE"
echo -e "\t-k\tstart the redis-server and promote it to MASTER"
echo -e ""
exit $E_INVALID_ARGS
}
for arg in "$@"
do
case $arg in
-m) arg_m=true;;
-s) arg_s=true;;
-k) arg_k=true;;
*) usage;;
esac
done
if [ $arg_m ]; then
echo -e "Promoting redis-server to MASTER\n"
start_redis
wait
start_master
elif [ $arg_s ]; then
echo -e "Promoting redis-server to SLAVE\n"
start_redis
wait
start_slave
elif [ $arg_k ]; then
echo -e "Starting redis-server and promoting to MASTER\n"
start_redis
wait
start_master
else
usage
fi
