首页 >
数据库 >
mysql
go-mysql-elasticsearch 同步mysql数据到es
时间:2019-05-21 15:37:26 点击: 来源: 作者:
项目github地址:https://github.com/siddontang/go-mysql-elasticsearch go-mysql-elasticsearch的基本原理是:如果是第一次启动该程序,首先使用mysqldump工具对源mysql数据库进行一次全量同步,通过elasticsearch ...
go-mysql-elasticsearch的基本原理是:如果是第一次启动该程序,首先使用mysqldump工具对源mysql数据库进行一次全量同步,通过elasticsearch client执行操作写入数据到ES;然后实现了一个mysql client,作为slave连接到源mysql,源mysql作为master会将所有数据的更新操作通过binlog event同步给slave, 通过解析binlog event就可以获取到数据的更新内容,之后写入到ES.
另外,该工具还提供了操作统计的功能,每当有数据增删改操作时,会将对应操作的计数加1,程序启动时会开启一个http服务,通过调用http接口可以查看增删改操作的次数。
使用事项:
1. mysql binlog必须是ROW模式
2. 要同步的mysql数据表必须包含主键,否则直接忽略,这是因为如果数据表没有主键,UPDATE和DELETE操作就会因为在ES中找不到对应的document而无法进行同步
3. 不支持程序运行过程中修改表结构
4. 要赋予用于连接mysql的账户RELOAD权限以及REPLICATION权限, SUPER权限:
安装:
yum -y install go
cd go-mysql-elasticsearch
make #make后才会出现bin文件夹
vi etc/river.toml
# MySQL address, user and password
# user must have replication privilege in MySQL.
my_addr = "127.0.0.1:3307"
my_user = "root"
my_pass = "a123456"
my_charset = "utf8"
# Set true when elasticsearch use https
#es_https = false
# Elasticsearch address
es_addr = "127.0.0.1:9200"
# Elasticsearch user and password, maybe set by shield, nginx, or x-pack
es_user = "elastic"
es_pass = "a123456"
# Path to store data, like master.info, if not set or empty,
# we must use this to support breakpoint resume syncing.
# TODO: support other storage, like etcd.
data_dir = "./var"
# Inner Http status address
stat_addr = "127.0.0.1:12800"
# pseudo server id like a slave
server_id = 1001
# mysql or mariadb
flavor = "mysql"
# mysqldump execution path
# if not set or empty, ignore mysqldump.
mysqldump = "mysqldump"
# if we have no privilege to use mysqldump with --master-data,
# we must skip it.
#skip_master_data = false
# minimal items to be inserted in one bulk
bulk_size = 128
# force flush the pending requests if we don't have enough items >= bulk_size
flush_bulk_time = "200ms"
# Ignore table without primary key
skip_no_pk_table = false
# MySQL data source
[[source]]
schema = "test123"
# Only below tables will be synced into Elasticsearch.
# "t_[0-9]{4}" is a wildcard table format, you can use it if you have many sub tables, like table_0000 - table_1023
# I don't think it is necessary to sync all tables in a database.
tables = ["min_video_operate"]
# Below is for special rule mapping
# Very simple example
#
# desc t;
# +-------+--------------+------+-----+---------+-------+
# | Field | Type | Null | Key | Default | Extra |
# +-------+--------------+------+-----+---------+-------+
# | id | int(11) | NO | PRI | NULL | |
# | name | varchar(256) | YES | | NULL | |
# +-------+--------------+------+-----+---------+-------+
#
# The table `t` will be synced to ES index `test` and type `t`.
[[rule]]
schema = "test123"
table = "min_video_operate"
index = "min_video_operate"
type = "min_video_operate"
# Wildcard table rule, the wildcard table must be in source tables
# All tables which match the wildcard format will be synced to ES index `test` and type `t`.
# In this example, all tables must have same schema with above table `t`;
# Simple field rule
#
# desc tfield;
# +----------+--------------+------+-----+---------+-------+
# | Field | Type | Null | Key | Default | Extra |
# +----------+--------------+------+-----+---------+-------+
# | id | int(11) | NO | PRI | NULL | |
# | tags | varchar(256) | YES | | NULL | |
# | keywords | varchar(256) | YES | | NULL | |
# +----------+--------------+------+-----+---------+-------+
#
#[[rule]]
#schema = "test"
#table = "tfield"
#index = "test"
#type = "tfield"
#[rule.field]
# Map column `id` to ES field `es_id`
#id="es_id"
# Map column `tags` to ES field `es_tags` with array type
#tags="es_tags,list"
# Map column `keywords` to ES with array type
#keywords=",list"
# Filter rule
#
# desc tfilter;
# +-------+--------------+------+-----+---------+-------+
# | Field | Type | Null | Key | Default | Extra |
# +-------+--------------+------+-----+---------+-------+
# | id | int(11) | NO | PRI | NULL | |
# | c1 | int(11) | YES | | 0 | |
# | c2 | int(11) | YES | | 0 | |
# | name | varchar(256) | YES | | NULL | |
# +-------+--------------+------+-----+---------+-------+
#
#[[rule]]
#schema = "test"
#table = "tfilter"
#index = "test"
#type = "tfilter"
# Only sync following columns
#filter = ["id", "name"]
# id rule
#
# desc tid_[0-9]{4};
# +----------+--------------+------+-----+---------+-------+
# | Field | Type | Null | Key | Default | Extra |
# +----------+--------------+------+-----+---------+-------+
# | id | int(11) | NO | PRI | NULL | |
# | tag | varchar(256) | YES | | NULL | |
# | desc | varchar(256) | YES | | NULL | |
# +----------+--------------+------+-----+---------+-------+
#
#[[rule]]
#schema = "test"
#table = "tid_[0-9]{4}"
#index = "test"
#type = "t"
# The es doc's id will be `id`:`tag`
# It is useful for merge muliple table into one type while theses tables have same PK
#id = ["id", "tag"]
es操作:需要创建好索引,不然会出错。
PUT min_video_operate
启动程序:
./bin/go-mysql-elasticsearch -config=./etc/river.toml & #启动,最好放后台
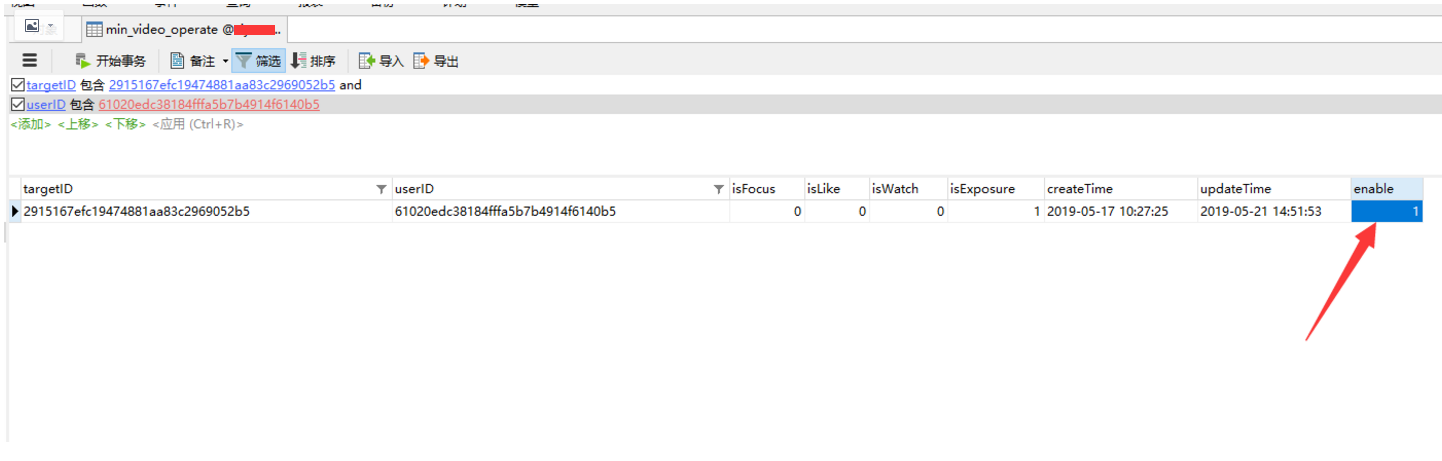
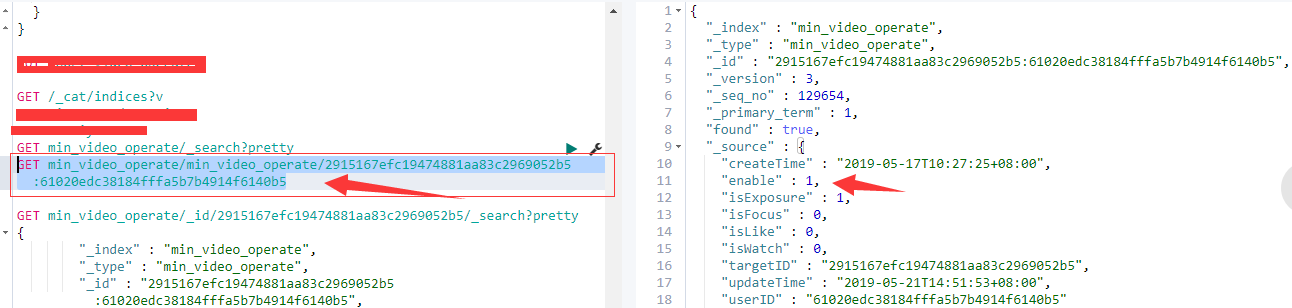
测试:第一次启动后会全量同步,同步完成后可增,删,改相关信息并查看同步结果。
GET min_video_operate/min_video_operate/2915167efc19474881aa83c2969052b5:61020edc38184fffa5b7b4914f6140b5
#上面查询中依次是 “ 表名/索引名/targetID:userID” 可根据自己情况调整,修改
”您可通过以下微信二维码,赞赏作者“