分布式文件系统很多,包括GFS,HDFS,淘宝开源的TFS,Tencent用于相册存储的TFS (Tencent FS,为了便于区别,后续称为QFS),以及Facebook Haystack。其中,TFS,QFS以及Haystack需要解决的问题以及架构都很类似,这三个文件系统称为Blob FS (Blob File System)。本文从分布式架构的角度对三种典型的文件系统进行对比。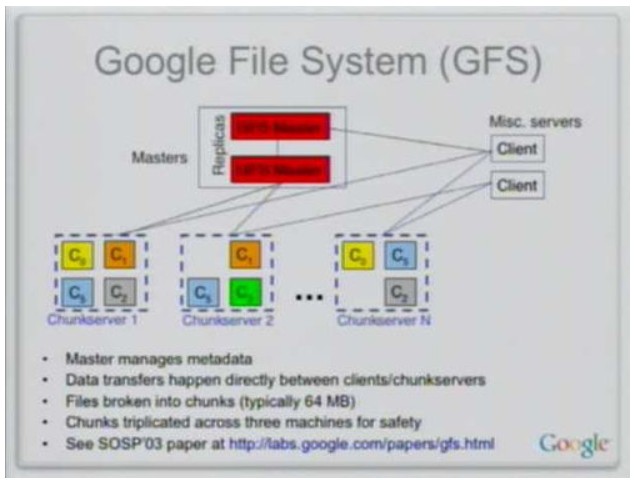
我们先看GFS和HDFS。HDFS基本可以认为是GFS的一个简化版实现,二者因此有很多相似之处。首先,GFS和HDFS都采用单一主控机+多台工作机的模式,由一台主控机(Master)存储系统全部元数据,并实现数据的分布、复制、备份决策,主控机还实现了元数据的checkpoint和操作日志记录及回放功能。工作机存储数据,并根据主控机的指令进行数据存储、数据迁移和数据计算等。其次,GFS和HDFS都通过数据分块和复制(多副本,一般是3)来提供更高的可靠性和更高的性能。当其中一个副本不可用时,系统都提供副本自动复制功能。同时,针对数据读多于写的特点,读服务被分配到多个副本所在机器,提供了系统的整体性能。最后,GFS和HDFS都提供了一个树结构的文件系统,实现了类似与Linux下的文件复制、改名、移动、创建、删除操作以及简单的权限管理等。
然而,GFS和HDFS在关键点的设计上差异很大,HDFS为了规避GFS的复杂度进行了很多简化。首先,GFS最为复杂的部分是对多客户端并发追加同一个文件,即多客户端并发Append模型 。GFS允许文件被多次或者多个客户端同时打开以追加数据,以记录为单位。假设GFS追加记录的大小为16KB ~ 16MB之间,平均大小为1MB,如果每次追加都访问GFS Master显然很低效,因此,GFS通过Lease机制将每个Chunk的写权限授权给Chunk Server。写Lease的含义是Chunk Server对某个Chunk在Lease有效期内(假设为12s)有写权限,拥有Lease的Chunk Server称为Primary Chunk Server,如果Primary Chunk Server宕机,Lease有效期过后Chunk的写Lease可以分配给其它Chunk Server。多客户端并发追加同一个文件导致Chunk Server需要对记录进行定序,客户端的写操作失败后可能重试,从而产生重复记录,再加上客户端API为异步模型,又产生了记录乱序问题。Append模型下重复记录、乱序等问题加上Lease机制,尤其是同一个Chunk的Lease可能在Chunk Server之间迁移,极大地提高了系统设计和一致性模型的复杂度。而在HDFS中,HDFS文件只允许一次打开并追加数据,客户端先把所有数据写入本地的临时文件中,等到数据量达到一个Chunk的大小(通常为64MB),请求HDFS Master分配工作机及Chunk编号,将一个Chunk的数据一次性写入HDFS文件。由于累积64MB数据才进行实际写HDFS系统,对HDFS Master造成的压力不大,不需要类似GFS中的将写Lease授权给工作机的机制,且没有了重复记录和乱序的问题,大大地简化了系统的设计。然而,我 们必须知道,HDFS由于不支持Append模型带来的很多问题,构建于HDFS之上的Hypertable和HBase需要使用HDFS存放表格系统的 操作日志,由于HDFS的客户端需要攒到64MB数据才一次性写入到HDFS中,Hypertable和HBase中的表格服务节点(对应于Bigtable中的Tablet Server)如果宕机,部分操作日志没有写入到HDFS,可能会丢数据。其次是Master单点失效的处理 。GFS中采用主从模式备份Master的系统元数据,当主Master失效时,可以通过分布式选举备机接替主Master继续对外提供服务,而由于Replication及主备切换本身有一定的复杂性,HDFS Master的持久化数据只写入到本机(可能写入多份存放到Master机器的多个磁盘中防止某个磁盘损害),出现故障时需要人工介入。另外一点是对快照的支持 。GFS通过内部采用copy-on-write的数据结构实现集群快照功能,而HDFS不提供快照功能。在大规模分布式系统中,程序有bug是很正常的 情况,虽然大多数情况下可以修复bug,不过很难通过补偿操作将系统数据恢复到一致的状态,往往需要底层系统提供快照功能,将系统恢复到最近的某个一致状 态。总之,HDFS基本可以认为是GFS的简化版,由于时间及应用场景等各方面的原因对GFS的功能做了一定的简化,大大降低了复杂度。
Blob File System的需求和GFS/HDFS其实是有区别的。GFS和HDFS比较通用,可以在GFS和HDFS上搭建通用的表格系统,如 Bigtable,Hypertable以及HBase,而Blog File System的应用场景一般为图片,相册这类的Blob数据。GFS的数据是一点一点追加写入到系统的,而Blob数据一般是整个Blob块一次性准备好 写入到Blob文件系统,如用户上传一个图片。GFS是大文件系统,考虑吞吐量,可以在上面搭建通用KV或者通用表格系统,而Blob文件系统是小文件系 统,一般只是用来存放Blob数据。GFS与Blob FS看起来也有很多相似之处,比如GFS和TFS目前都采用单一主控机+多台工作机的模式,主控机实现数据的分布、复制、备份决策,工作机存储数据,并根 据主控机命令进行数据存储,迁移等,但是,二者的区别还是比较大的。由于业务场景不同,二者面临的问题不同,在Blob FS中,由于整个Blob块数据一次准备就绪,Blob FS的数据写入模型天生就是比较简单,每次写入都请求Master分配Blob块编号及写入的机器列表,然后一次性写入到多台机器中。然而,Blob FS面临的挑战是元数据过于庞大的问题 。由于Blob FS存储的Blob块个数一般很大,比如TFS中存储了百亿级的淘宝图片,假设每张图片的元数据占用20字节,所有的元数据占用空间为10G * 20 = 200GB,单机内存存放不下,并且数据量膨胀很快。因此,TFS, QFS以及Facebook Haystack都采取了几乎相同的思路,Blob FS不存放元数据,元数据存放到外部的系统中。比如,淘宝TFS中的元数据为图片的id,这些图片id存放在外部数据库,比如商品库中,外部数据库一般是Oracle或者Mysql sharding集群。Blob FS内部也是按照Chunk块组织数据,每个Blob文件是一个逻辑文件,内部的Chunk块是一个物理文件,多个逻辑文件共享同一个物理文件,从而减少单个工作机的物理文件的个数。由于所有物理文件的元数据都可以存放到内存中,每次读取Blob逻辑文件只需要一次磁盘IO ,基本可以认为达到了最优。
总之,HDFS和GFS可以认为是类似的,GFS基本覆盖了HDFS的功能,而Blob FS和GFS面临的问题不同,设计的出发点也不一样,两类系统有本质的差别。如果需要将GFS和Blob FS统一成一套系统,这套系统需要同时支持大文件和小文件,且这套系统因为存放的元数据量太大,Master节点本身也需要设计成分布式。这个大一统的系统实现复杂度非常高,目前只有GFS v2有可能可以做到。






