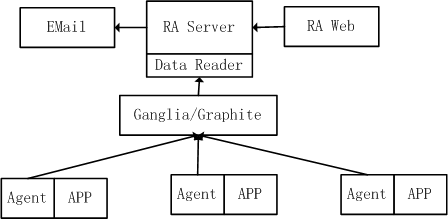
图1、系统框架示意图
Ganglia、Graphite等系统,通过各自的Agent收集各个应用的核心指标,然后通过可视化界面展示指标的趋势图形。但是,诸如Ganglia、Graphite之类的系统一般只负责收集和展示,缺乏在指标异常时的报警功能。RA 则直接读取Ganglia、Graphite等系统收集的数据,然后根据设置的规则检测异常并主动报警。RA由两部分组成,RA server 负责加载报警规则并读取指标数据,在检测到异常时,发送报警。报警方式可以配置为邮件,也可以扩展成其他方式。RA Web 则为用户的使用界面,方便用户配置各种规则和对系统的控制。为方便应用方进一步扩展,将数据读取部分Data Reader抽象成独立的插件,用户可以通过撰写新的插件来支持其它类型的时间序列数据。
用户增删监控指标以及修改参数等都比较频繁,RA 提供一个可视化的操作界面以便于用户操作。主界面如图2所示,RA界面比较简洁,提供策略的配置和修改、监控项屏蔽以及对RA自身的状态控制等操作。为快速找到监控项,左侧列表栏提供快速检索功能,对有成百上千个监控应用的系统极为有用。在右上角提供对一个监控指标的查询操作,帮助用户检索到含特定字符串的监控指标。针对一个监控指标,可以快速查看、修改、删除和屏蔽。也可以克隆一个监控指标,以实现快速生成新的监控指标。更多功能及使用方式,可以参考RA的用户文档。 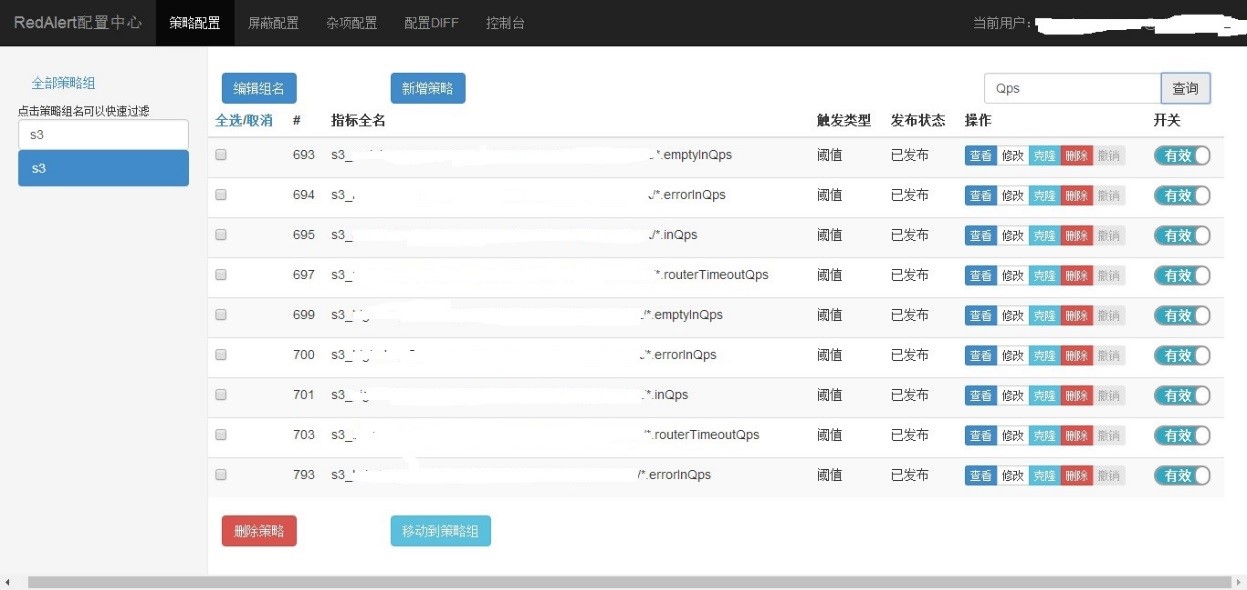
图2、RA 用户界面
RA提供五种常用的报警策略:阈值、趋势、环比、可用性、奇异点。
阈值检测:阈值是最常用的报警策略,通常情况下,一个指标在一个范围内波动为正常,超出该范围则为异常,需要报警,例如系统的QPS。有些指标则期望最大值不大于某个值,或者最小值不低于某个值,诸如CPU、延迟等。这些需求都可以通过阈值检测策略来轻松满足。
趋势检测:大部分系统指标都是一条相对平滑的曲线,极少出现断崖式突增或突降。如果出现突增或突降,基本为系统出现异常情况,比如系统突然受到大量爬虫抓取等导致访问量突增。此时,如果阈值报警过于宽松,则该异常很难发现。则需要通过趋势检测策略来发现这些潜在问题。趋势检测策略通过历史数据预测下一刻的值,如果系统实际值与预测值相差范围过大,则认为出现异常。该策略能及时发现系统中存在的潜在问题,应用也比较广泛。
可用性检测:大部分系统都具备横向扩展的能力,通常由多个功能相同节点来同时提供服务以便提升服务能力。例如,采用多个Redis进程组成服务集群,以提供数据存取服务。如果部分机器宕机,服务进程停止,则影响服务的可用性。RA通过判断正常汇报一个指标的机器数量,可以检测出异常服务。通过设置同一指标汇报进程的最小值来进行可用性报警,当数量小于一个阈值时,则认为整个服务集群存在风险。
奇异点检测:在一个服务集群中相同功能的节点,其各项指标应该相近,否则可能存在异常节点。例如,在同一个集群中的上千个节点中,有个别节点的延迟大于其它节点,则该节点需要尽快处理。RA 通过比较所有节点汇报上来的相同指标,参考配置的差异范围,如果超过配置的范围,则判定为异常节点并报警。对于发现硬件损坏诸如磁盘变慢,或者外部进程干扰诸如IO等比较有效。
周期检测:大量的服务指标都存在周期性变化,通常随外部用户访问量的高低峰出现有规律的波动。比如白天可能访问量相对较高,深夜则相对较低。在一个周期内,指标环比差异应该不大。RA通过对比相近周期内,同一时间点的指标差异,来发现服务异常。
为更灵活的设置报警策略,RA可以配置该一条策略的生效时间段,既可以配置一个时间段,也可以设置多个时间段。在配置要监控的指标名时,系统支持正则匹配,方便配置一系列的指标监控。不同的报警项,可以设置不同的指标采样间隔、最短告警间隔等以便于调整报警的灵敏度和抑制过多的报警信息。异常报警是大规模系统不可或缺的部分,神马诸多业务中,99%以上的异常问题由RA发现并报警。RA开源之后,期望能让更多有相同需求的业务受益,也期望RA自身能得到更进一步的完善。
相关链接:
RedAlert:https://github.com/alibaba/RedAlert
Ganglia:http://ganglia.info/
Graphite:http://graphiteapp.org/






